What Is Global Conceptual Schema
what is global conceptual schema
Introduction to CUBRID Cluster | CUBRID Blog
We have great news this week. It is time to announce what we have been working on aside from improving the CUBRID Database. The CUBRID Cluster project is approaching to its public release.
About a year ago we announced the start of the CUBRID Cluster Project. Since then it has continuously evolved and soon to finalize its 4th Milestone.

The significance of the 4th Milestone (M4) is that CUBRID Cluster is being integrated into and tested on the real-world Analytics service. Once we accomplish this step we plan to publicly release an alpha version of CUBRID Cluster.
Background and Goal
Background
In the Web Services environment the volume of the data increases very fast, and oftentimes it is never deleted. The bigger the data, the slower the performance of the database storage system. To maintain the performance, service providers have two options:
- Scale up (or scale vertically), i.e. buy a number of more powerful and more expensive server hardware.
- Scale out (or scale horizontally), i.e. add cheap server hardware and use a distributed software application to handle these nodes.
Unless the service provider is a large corporation, it is often more rational to follow the second option, though it requires sophisticated software and expertise. When scaling out it is necessary to instruct the application to leverage the newly added nodes, which implies the code change. Unless the system provides hot swapping, such as Erlang, it might be necessary to restart the system.
To ensure availability and stability a clustering software can be used to perform horizontal scale-out without application modification. This is what CUBRID Cluster is developed for.
Goal
The goal is to have:
- Dynamic Scalability
No need for application change. - Transparency to applications
- Location transparency
Applications do not need to know where the actual database is physically located. There is only one global entry point for applications to know which is realized through Global Schema. - Replication transparency
Database replication appears to the application as a single system. - Relocation transparency
Moving a database while in use should not be noticeable to the application. - Failure transparency
Always try to hide any failure and recovery of database systems. - Volume Size and Performance
- When performance is the same, Cluster can store more data.
- When data size is the same, Cluster can provide higher performance.
- Distributed Partitioning
Partitions can be seamlessly created with a simple SQL command. - Load Balancing
Cluster can provide automatic load balancing. - Other
- Cluster Management Node
- Heartbeat and High-Availability
The following slide illustrates the current architecture of CUBRID Database and the architecture of CUBRID Cluster.

As of M4 we have implemented the following major features in CUBRID Cluster:
- Global Schema
- Global Database
- Distributed Partitioning
- Global Transaction
- Dynamic Scalability
- Global serial & global index
Now we have started to work on these features:
- Support for High-Availability
- Cluster Management Node
- Dead-lock detection
CUBRID Cluster Concept
Global Schema
Generally, the global schema can be defined as a global view of distributed data sources, or a schema integration of underlying databases. In CUBRID Cluster, global schema is a single representation of data structures in all nodes where each node has its own database and schema. Users can access any databases through a single schema regardless of and without knowing the location of the distributed data (location transparency). Just like local schema, global schema is stored as a system catalog, and defines entities and relationships by tables, fields, indexes, serial and other elements.
Querying Global Schema
Schema is represented to users as a system catalog. Querying schema requires to know the structure of system catalog tables.
SELECT * FROM _db_class; SELECT * FROM _db_attributes; SELECT * FROM db_partitions;
Querying Global Table
SELECT * FROM gclass WHERE …; SELECT * FROM gclass_a, gclass_b WHERE gclass_a.att = gclass_b.att; SELECT * FROM gclass, lclass WHERE glcass.att = lclass.att;
DML on Global Table
INSERT INTO gclass VALUES (…); INSERT INTO gclass_a SELECT * FROM gclass_b WHERE …; UPDATE gclass SET … WHERE …; DELETE FROM gclass WHERE …;

Global Database
Global database is a logical concept to represent a database managed by the CUBRID Cluster system. Each node in the Cluster system has its own local database, which are physical. A local database should be registered to a global database.

Distributed Partition Concept
Creating Global Partitioned Table
A global partitioned table is a distributed partition table. Data in different partitions can be stored in different server nodes. A user can access the global table from any node within the cluster.
Example:
CREATE GLOBAL TABLE gt1 (id int, …) partition by hash (id) partitions 3 ON NODE 'server1', 'server2', 'server3';
- Data in gt1__p__p0, will be stored in server1;
- Data in gt1__p__p1, will be stored in server2;
- Data in gt1__p__p2, will be stored in server3;

Global Transaction
A global transaction will be divided into several local transactions which run on different server nodes. Global transaction makes sure that every server node in CUBRID Cluster is consistent before or after the global transaction. The process of global transaction is transparent to application.
Dynamic Scalability
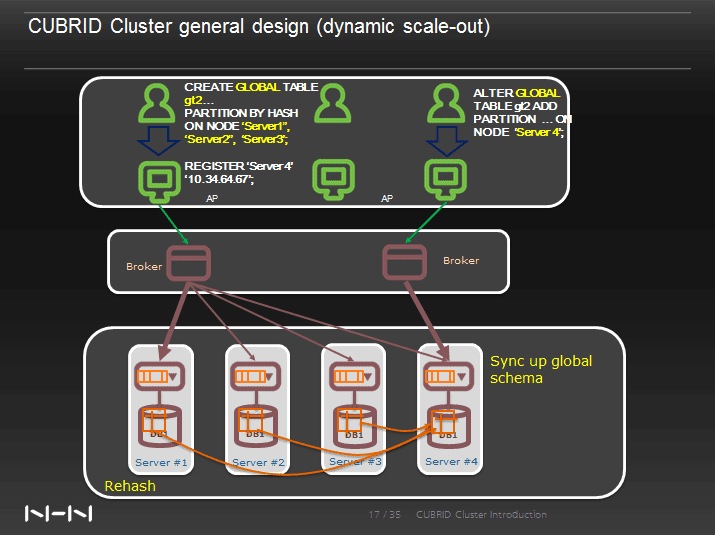
Dynamic scalability allow user to extend or shrink server nodes in CUBRID Cluster without stopping the system. After the new server node is added to the Cluster, user can instantly access and query global table from this new node.
User Specs
Registering Local DB into Global DB (Cluster)
In order use the Global Schema feature of CUBRID Cluster, the first thing to do is to register local databases into the global database. The global database is not a physical database. It is a concept of clustering existing local databases. A global table is an element or a part of the global schema.
REGISTER NODE'node1' '10.34.64.64'; REGISTER NODE'node2' 'out-dev7';
Creating Global Table/Global Partition table
CREATE GLOBAL TABLE gt1 (…) ON NODE'node1'; CREATE GLOBAL TABLE gt2 (id INT primate key, …) partition by hash (id) partitions 2 ON NODE 'node1', 'node2';
DML operations (INSERT/SELECT/DELETE/UPDATE)
Dynamic Scalability is very easy in CUBRID Cluster. A simple SQL query will sync the global schema and rehash the data from existing partitions and distribute it to the new node.
/* add a new server node to the global database */ REGISTER 'node3' '10.34.64.66'; /* adjust data to new server node */ ALTER GLOBAL TABLE gt2 ADD PARTITION PARTITIONS 1 ON NODE 'node3';
CUBRID Cluster General Design
When performing DDL operations, the CUBRID Broker may communicate with each node, though there is a default server to accept the requests.

For example, during the SELECT operation, the Broker requesta the data from the Global Schema which sends remote scan requests to all the nodes to retrieve the data.

Additionally, if ORDER BY clause is present in the query, the Cluster will perform partial sorting on each of the node locally. Then once the results are gathered from the nodes, the default server will merge the results and perform the final sorting and return the resultset.

So basicly there are four steps:
- One C2S communication between the Broker and the Default server;
- And three S2S communications between cluster nodes.
On the left side of the following slide you can see the process of retrieving the data using the partition key. It is known to be not fast enough. To improve the performance, we are working on eliminating one server level step of sending the remote scan request. Instead the Broker will directly send the request to the necessary server, which will do the scan and return the data. No remote scan will take place, thus higher performance can be achieved.

When more partitions are added, the Cluster will sync the global schema to the newly added nodes and rehash the data from existing partitions and distribute it to the new node, thus providing dynamic scale-out.
The Status of the Cluster Project
The CUBRID Cluster project is based on the code of CUBRID 8.3.0.0337 released on October 4, 2010. The Quality Assurance requires it to pass three kinds of test:
- All CUBRID regression test cases.
- All CUBRID Cluster QA and dev functions test cases.
- All QA Performance test cases.
Milestone 1
- Achievements:
- Opened the source on http://sourceforge.net/projects/cubridcluster (including code, wiki, bts, forum)
- Created a general design for CUBRID Cluster
- Implemented the global database
- Implemented the system catalog extension and support for global table DDL
- Implemented support for basic DML statement (insert/select/delete/update) for a global table
- Implemented support for s2s communication (server transfer data)
- Others:
- Source lines of code (LOC): 19246 (add 11358, del 817, mod 7071)
- Add Chinese msg (LOC): 7507
- BTS issues numbers: 178 issues
- Check-in in subversion: 387 times
Milestone 2
- Achievements:
- Implemented distributed partition table by hash (basic DDL and DML)
- Support constraints (global index, primary key, unique), query with index
- Support global serial
- Support global transaction (commit, rollback)
- Refactor s2s communication (add s2s communication interface and connection pooling)
- Support all SQL statements for NHN Café service.
- Pass all QA functional testing
- Others:
- Source lines of code (LOC): 20242 (add 8670, del 4385, mod 7187)
- BTS issues numbers: 241 issues
- Fix QA bugs: 43 bugs
- Check-in in subversion: 461 times
Milestone 3
- Achievements:
- Performance improvement for M2 (DDL, query, server side insert, 2PC)
- Refactor global transaction, support savepoint and atomic statement
- Implement dynamic scalability (register/unregister node, add/drop partition)
- Support load/unloaddb, killtran
- Others Features : (auto increment, global deadlock timeout)
- Passed QA functional and performance testing
- Others:
- Source lines of code (LOC): 11518 (add 7065, del 1092, mod 3361)
- BTS issues numbers: 165 issues
- Fixed QA bugs: 52 bugs
- Check-in in subversion: 461 times
Milestone 4 (ongoing)
- Goal
- Provide data storage engine for NHN nReport Project
- Performance improvement for order by and group by statement
- Support big table join small table (global partition table join with non-partition table)
Performance results
Test Environment
- 3 Server nodes (10.34.64.201/202/204):
- CPU : Intel(R) Xeon(R) CPU E5405 @2.00GHz
- Memory: 8G
- Network: 1000 Mbps
- OS: Center 5.5 (64bit)
- Configure: data_buffer_pages=1,000,000
- Table size: 100,000 and 10,000,000 rows
- Data size: 108M (total 207M) and 9.6G (total 30G)
- Each thread runs 5000 times

Test Scenario
- Create table statement:
- Cluster M3:
CREATE GLOBAL TABLE t1 (a INT, b INT, c INT, d CHAR(10), e CHAR(100), f CHAR(500), INDEX i_t1_a(a), INDEX i_t1_b(b)) PARTITION BY HASH(a) PARTITIONS 256 ON NODE 'node1', 'node2', 'node3';
- CUBRID R3.0:
CREATE TABLE t1 (a INT, b INT, c INT, d CHAR(10), e CHAR(100), f CHAR(500), INDEX i_t1_a(a), INDEX i_t1_b(b)) PARTITION BY HASH(a) PARTITIONS 256;
- Test statements:
- Select partition key column:
SELECT * FROM t1 WHERE a = ?
- Select non-partition key column:
SELECT * FROM t1 WHERE b = ?
- Select non-partition key column by range:
SELECT * FROM t1 WHERE b BETWEEN ? AND ?
- Insert with auto commit:
INSERT INTO T1 VALUES (?, ?, ?, ?, ?, ?);
Test Results
The following screenshot illustrate the comparative performance results for the above test scenario. CUBRID Cluster shows some 2 to 3 times higher TPS that CUBRID 8.3.0.

Average Response Time in Cluster is likewise significantly lower than in CUBRID 8.3.0.

Test Environment
In the above test environment we have used 3 nodes. We have rerun the same test on more powerful hardware in a cluster of 8 nodes with the following configurations. At the same time we have increased the data size up to 100 million records.
- Server nodes (10.34.64.49/50 …/58):
- CPU : Intel(R) Xeon(R) CPU E564data_buffer_pages=1,000,000
- Table size: 100,000,000 rows
- Data size: 88G (total size: 127G)
Test Results


Conclusion
CUBRID Cluster is still a project under development. It has reached its M4 stage when we started to deploy CUBRID Cluster for a real-world Analytics service. The current version supports all SQL statements of NHN Cafe service. CUBRID Cluster provides location transparency through a global schema and global database concepts. Current CUBRID Database applications can use CUBRID Cluster easily without much modification. The Cluster can store more data than CUBRID Database maintaining the same performance, or can provide higher performance than CUBRID Database for the same amount of data. Distributed partition is very easy to apply on services. Thus, CUBRID Cluster can easily scale out.
As a result the service providers can save big chunk of their cost by deploying CUBRID Cluster.
Since CUBRID Cluster is still a work in progress, we have a lot things to do. At this moment JOINs are not supported. We are working on providing support for big table join small table (global partition table join with non-partition table). To retreive the database the Cluster system performs four steps: 1 of them is on client-server side, while 3 - server side. Server-to-server communication may lead to increased network cost, while 2PC will write many logs which may lead to increased IO cost. As explained above we are working on improving the performance of ORDER BY and GROUP BY statement which will allow us to eliminate one of the server side steps.
Further plans also include:
- Performance improvement
- Support HA for each server node in CUBRID Cluster
- Support Load balance (write to active server/read from standby server)
- Support distributed partition by range/list
- Support global user
- Support backup/restore DB
Milestone 4 will last until the end of October, 2011. We plan complete the deployment of CUBRID Cluster as a data storage engine for NHN nReport service. You can find more information in the following presentation.
If you are interested in more detailed explanation on how all the things are implemented in CUBRID and CUBRID Cluster, see the following presentation. It will explain in details CUBRID Architecture, its source code structure and management components.
Overall Structure
- Query Processing Component
- Transaction Management Component
- Server Storage Management Component
- Client Storage Management Component
- Object Management Component
- Job and Thread Management Component
- Client-Server Communication Layer
- Broker Component
We also preapared a demo video which demonstrates how easy is to manage cluster of nodes with CUBRID Cluster. We will publish it soon. Staty tuned!
0 コメント:
コメントを投稿